How This Library Works
Changes
| Version | Date | Change | Author |
|---|---|---|---|
| v1 | 2026-05-06 | Initial draft — two-poster methodology page covering knowledge architecture and contribution loop. Archived. | Editorial team |
| v2 | 2026-05-24 | Expanded into canonical doctrine — added explicit verification protocol, propagation system, version permanence commitment, submission pathway, and participant roles; preserved v1 architecture and contribution sections. | Editorial team |
America's School Trust Library is unusual among libraries. It is built on an architecture that turns scattered primary sources — statutes, court opinions, agency reports, historical maps, period newspapers, oral histories, expert declarations — into the essays, dossiers, and reference works visitors read. Every claim cites its source. Every figure has an anchor. The architecture is the same whether the visitor is a school-board member preparing for a vote, a journalist on the education beat, an attorney looking for case law, or a student writing a term paper.
This page exists because some visitors will reasonably want to know how the Library actually works — how a court opinion becomes a cited line in a Reading Room essay, how a state correspondent's note becomes a Newsroom item, how a state Department of Lands staff member's correction makes its way into the published record. The page is long because the answers matter. Subheads make it scannable.
Why now
Three things are true at once. First, school-trust litigation is moving in several states after decades of dormancy, and the people who need this evidence — counsel, board members, journalists, legislators, parents — have nowhere consolidated to find it. Second, the artificial-intelligence tools that finally make it possible to build a national reference library at small-team scale are mature enough this year to do the work, and not so mature that there is yet a standard of practice for how to use them responsibly in evidentiary writing. Third, a handful of people with the domain knowledge, the institutional memory, and the will to do it are alive and willing. The Library exists in the brief window where all three are true together.
That timing is also why this page is written the way it is. A visitor who has watched recent AI-generated content devalue what they read will reasonably want to know whether anything published here can be trusted. The honest defense is not assertion but protocol. What follows is the protocol, with the means to verify it independently.
The four layers in plain language
The Library has four working layers. None of them is exotic; the discipline is in keeping them separate and tracing claims through them.
Primary sources. The evidentiary floor: statutes, court opinions, agency annual reports, historical maps, expert declarations, period newspapers, oral histories. Nothing is altered here. Sources are catalogued, dated, and never edited. When the source is a scanned signed opinion, the text is OCR'd from the signed image and the image itself is preserved alongside the searchable text, so any visitor can check the conversion.
Canonical claims. Each settled fact, figure, or doctrinal proposition is atomized into its own record and cited back to one or more primary sources. The same claim can appear in many published works, but it lives in one place. When new evidence arrives, the claim updates and every downstream document that uses it inherits the update.
Finished documents. What you see when you visit the Library: the Reading Room essays, the per-state dossiers, the Atlas Room, the Counting House, the Map Room, the Newsroom entries, the Voices section, the books. Everything cites back through the canonical claims to the primary sources, so a visitor can always trace a claim to its origin.
Public surfaces. The websites and printed books through which finished documents reach readers. The same finished document may render as a web page on the Library, a printed chapter in Schools of the Republic, a Newsroom email, and a one-page handout for a board meeting. The text is the same; the presentation is fitted to the reader.
A claim moves through the four layers like this. A primary source enters at the bottom — say, a 2026 court opinion. An editor reads it, identifies the propositions it establishes or modifies, and either creates a new canonical claim or updates an existing one with a paragraph-level citation back to the opinion. Finished documents that depend on the affected claim are reviewed and revised. The revised documents are republished to the public surfaces. The path is short by design; long enough to enforce discipline, short enough to be auditable.
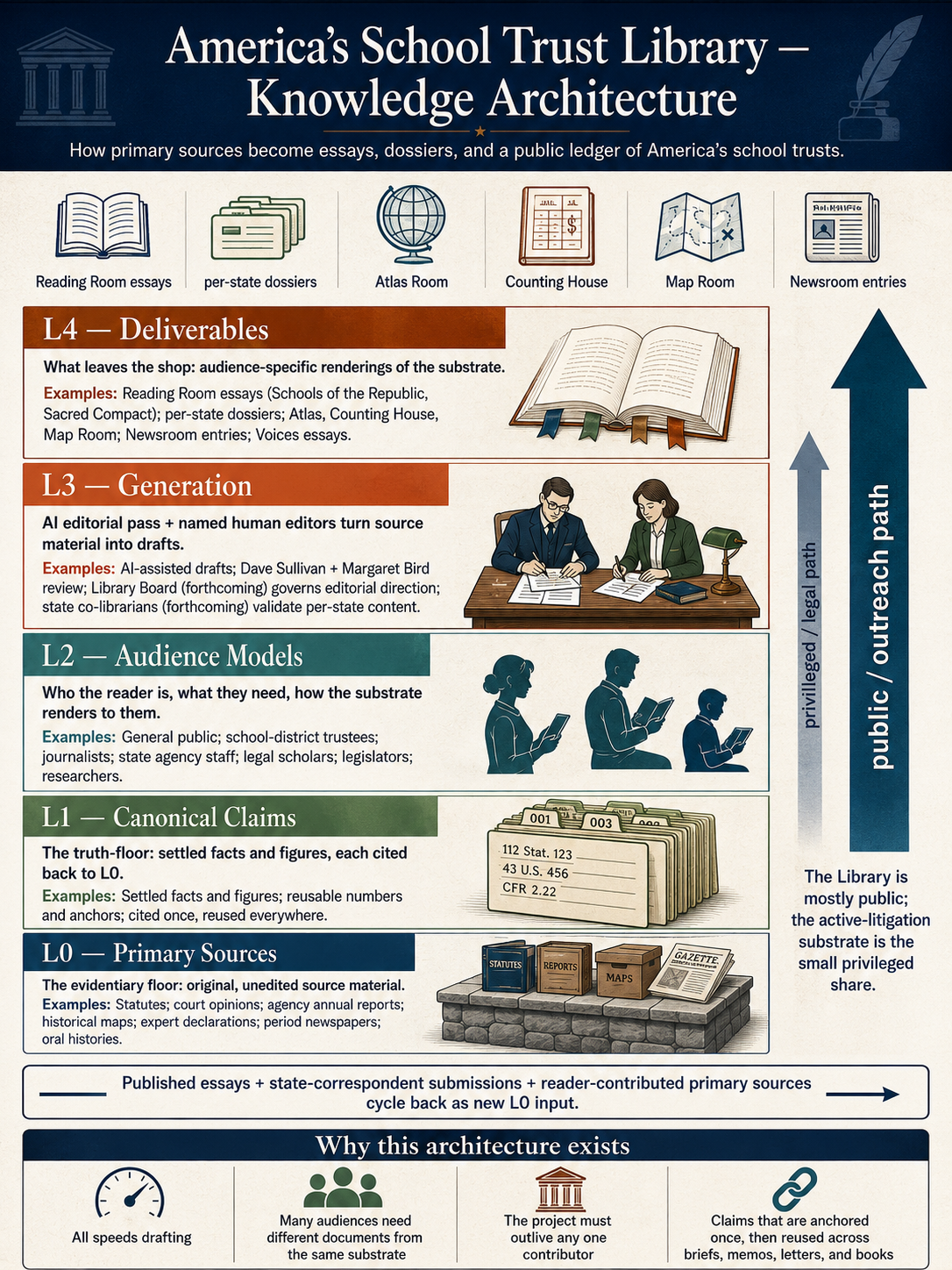
The architecture at work
A library has two sides. One is the standing collection — what is held, organized, and ready to be read at any moment. The other is the work of building, correcting, and extending the collection over time. The poster above shows the architecture at rest. The work side has its own structure.
The crew that does the work is small. A library does no work; a crew does. Six stations stand on the deck — primary-source ingestion, canonical-claim curation, editorial drafting, citation verification, propagation tracking, and public publication. The same person may stand at several stations, but each station has a named editor of record. No published claim has been generated without a human at the verification station passing it.
The persistent-memory note matters here. AI editorial tools have no working memory between sessions. The crew supplies it: a project memory file, a session-status file, a written record of editorial decisions, and the change log on every finished document. The AI tools are good at fast reading, drafting, and cross-referencing; the human editors are good at judgment, voice, and the question of whether the work is honest. The institutional memory lives in writing and in the crew.
How verification works
The most reasonable objection a first-time visitor will raise is whether the citations on this site are real. AI systems are known to invent plausible-sounding court opinions, statutes, and quotations that do not exist. The Library's protocol against that failure is explicit, and the defense is not "trust us" — it is "here is what we do, and here is how you can check."
Every legal citation is pulled from CourtListener. CourtListener is the Free Law Project's open database of primary judicial opinions. Before any court case enters a finished document on the Library, the case has been located on CourtListener and the opinion text downloaded from there. The citation in the finished document — court, parties, year, reporter, paragraph — is taken from the opinion as filed, not paraphrased from a secondary description.
Primary sources only. Quotations are taken from the source document itself, not from a treatise, news story, or AI summary describing the source. If a textbook says a court held X, we go to the court's opinion and confirm that the court actually held X before citing it. Secondary descriptions are useful for orientation; they are never the citation.
Paragraph-level anchoring. Every quoted passage or specific factual claim points to a specific paragraph in the underlying source. A reader who follows a footnote should be able to land on the same sentence the writer was looking at. Document-level citations ("see Lassen v. Arizona ex rel. Arizona Highway Department, 385 U.S. 458") are not enough on their own when the claim is specific.
OCR from signed opinions. When the underlying source is a scanned PDF of a signed court opinion or a historical document, the text used in the Library is OCR'd from the signed image, and the image is preserved alongside the searchable text. A visitor who suspects a transcription error can compare the two.
Nothing speculative. AI editorial assistance is used for drafting, structuring, and cross-referencing. It is not used to assert facts the editorial team has not confirmed against a primary source. If a passage would require a citation to support it and no source has been located, the passage is removed or marked unsupported. The Library does not file a claim into the record on the strength of an AI tool's general knowledge.
You can verify any citation yourself. Every finished document on the Library includes the citations needed to retrieve the underlying source. CourtListener is open to the public. Statutes are at the relevant state legislature's website or the federal code. Agency reports are at the agency. The Library's editorial discipline is checkable from outside.
The protocol is not exotic. It is what careful legal scholarship has always required. What is new is the willingness to write it down, publish it, and invite visitors to test it. The submission pathway described below is how a visitor who finds a citation that does not check out tells us, and how we correct it on the record.
How information enters and moves through the Library
When a new primary source enters the collection, the work is not finished — it is just beginning. A single new court opinion may bear on a dozen existing finished documents: a state dossier, three Reading Room essays, a Newsroom item from two months ago, a chapter in a book, a legislative primer. If the new source corrects or extends what those documents say, every one of them needs to be reviewed.
To make sure that review happens, an automatic check runs whenever a new primary source is added. The check looks across the existing collection for documents that cite, reference, or might be affected by the new material, and produces a list — a propagation log — of every document that should be evaluated. The log is kept in the open. Each entry records the new source, the documents flagged for review, and what was done (updated, reviewed and confirmed still accurate, or set aside with a note explaining why).
The same check runs in the other direction. When a finished document is corrected or extended, the propagation log records what changed and which other documents may inherit the change. This is how a correction made in one place does not silently leave a contradiction in another. The log is the record we keep to show the work.
The cadence is weekly. Outstanding items in the log are reviewed, worked through, and the public "Building the Library" page is updated with what was done. Nothing is automated to the point of being unsupervised — the check produces the list; the named editor does the review.
Versions and change history
Every finished document on the Library carries a version number and a change log. The change log is at the top of the document, immediately after the title. It records each version, the date of publication, what changed in that version, and who made the change. New versions append rows; old rows are never edited or removed.
The version history matters because the Library is built to be cited. A law-review article published in 2027 that cites a 2026 Reading Room essay needs the 2026 essay to remain findable, at its original URL, in the form it had when cited. Scholarly and legal citation depend on the cited document staying put. The Library's commitment is that prior versions of any finished document remain accessible at stable URLs indefinitely. A reader who wants the May 2026 version of Schools of the Republic will find it at its May 2026 address even after later versions ship.
Corrections are dated. The Library does not silently overwrite its record of what it once said. If a finished document made a factual error in version 1 and version 2 corrects it, the change log on version 2 records that the error was made, when, and how it was corrected. Version 1 remains accessible. A visitor curious about the institution's history of mistakes can read it.
This is not standard practice for websites, which tend to overwrite quietly and lose their history. It is standard practice for institutions that expect to be cited across time. The Library is built for that case.
How to submit something or propose a correction
The Library is built to grow, and the work of growing it is partly the responsibility of readers who know something the editors do not. There are two things the Library accepts: primary-source documents related to school trust lands, and factual corrections to existing finished documents.
What we accept. Primary sources — old land patents, historical agency reports, board minutes, period newspapers, deeds, court filings, oral histories, photographs of trust land, agency correspondence — that bear on the school trust lands of any of the roughly twenty states that received federal land grants for school support. Factual corrections to anything published on the Library, with the underlying source identified so we can verify and correct on the record.
What we do not accept through this channel. Op-eds, unsolicited analytical essays, opinion pieces, or proposals for new framings. The Library is an evidentiary collection. Original analysis enters through the editorial process, not through reader submissions. Writers who want to contribute analytical work should reach out to the editorial office directly to discuss.
The pathway. Submissions arrive through the submission form on this site. Each submission is routed into editorial intake, reviewed by a named editor, and either incorporated, declined with reasons, or set aside with a note. If incorporated, the propagation check described above runs across the collection, and any finished documents affected are updated. The submission, the editorial decision, and the resulting changes are recorded in the log.
Our commitment. We acknowledge every submission within seven days. We incorporate, decline with reasons, or place under continuing review within thirty days. If a submission requires longer evaluation — for example, a primary source whose provenance needs to be checked through an archive — we say so explicitly and give an expected timeline. We do not let submissions disappear silently into a queue.
What happens after. If the submission is incorporated, the contributor is named in the contributor record at the end of the affected document and in the public stewardship ledger. If the contributor prefers anonymity, that is honored. If the submission is declined, the contributor receives an explanation. The pathway is public and the decisions are recorded.
Roles for participants
People can take part in the Library in three named ways. Each has a different level of commitment and a different point of contact.
Submitter. Anyone may send a primary-source document or propose a correction to existing material. The submitter role requires no credentials, no ongoing commitment, and no prior relationship with the Library. A school-board member who notices a date error in their state's dossier, a retired teacher who has a 1923 board minute in a desk drawer, a graduate student who has tracked down an obscure historical map — all are submitters. Use the submission form. The Library handles the rest.
Cited author. If your published work — book, article, report, declaration — is cited on the Library, we want to verify the citation is accurate and used as you intended. If you would like to review how your work is cited, the editorial office will send you the relevant excerpts and the surrounding context, and any clarification you offer will be incorporated on the record. This is not a request for permission; it is an offer to be checked. Cited authors who notice a citation we missed are also welcome to send it in through the submission form.
Validator. Credentialed reviewers — legal scholars in school-trust or fiduciary law, historians of public-lands policy, state-chapter advocates with deep state-specific knowledge — who agree to review specific finished documents before they enter the canonical version. The validator role is by invitation and ongoing relationship. If you would consider taking on validator responsibility in your area of expertise, contact the editorial office directly. This program is being built deliberately as the Library finds its first validators.
Three forthcoming structural roles — Document Contribution Desk, State Correspondent, State Co-Librarian — sit alongside the three participant roles above and will open for applications as the institutional infrastructure is ready.
The contribution loop
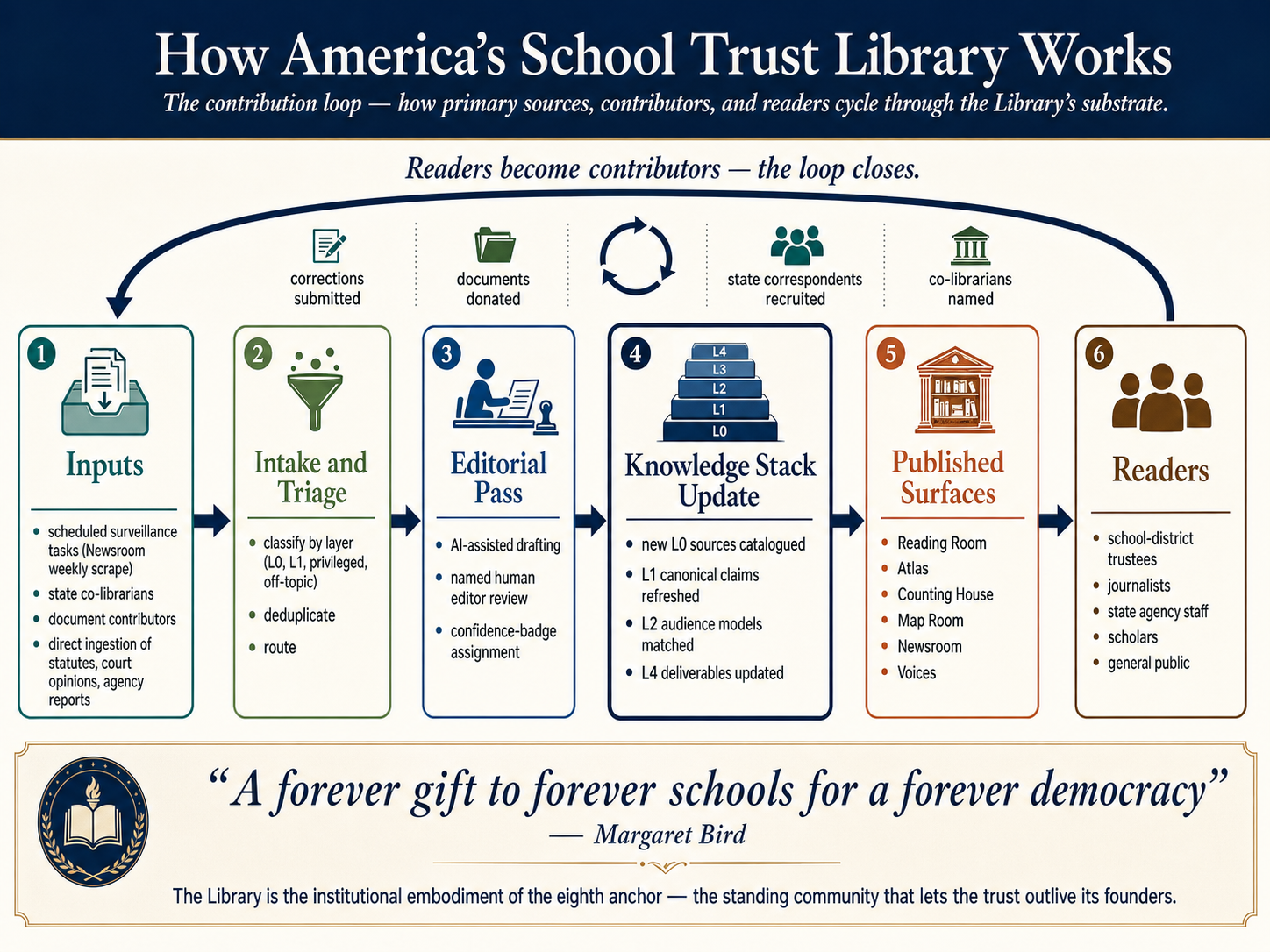
The architecture above shows what is held. The poster above shows how material moves through it. The flow has four phases.
Inputs. Material enters the Library from several sources: scheduled surveillance tasks (the Newsroom's weekly scan of state agency websites, legislative information systems, court dockets, regional press); state co-librarians (forthcoming — drawn primarily from State Departments of Lands and equivalent agencies, taking responsibility for their state's page); document contributors who hold primary sources in private hands; and ongoing direct ingestion of statutes, court opinions, and other public records.
Intake and editorial review. New material is triaged, classified by layer, checked for duplicates, and routed. The editorial pass that follows is AI-assisted but human-supervised: every published claim has been reviewed and approved by a named editor against the underlying primary source.
Update. Approved material updates the appropriate layer. New primary sources may produce new canonical claims, which may refresh finished documents that depended on the old claims — the propagation check described above is how that happens reliably.
Published surfaces. Updated content reaches readers through the Library's rooms — the Reading Room, the Atlas, the Counting House, the Map Room, the Newsroom, Voices — and through the printed books.
The loop closes when readers become contributors. A school-board member who corrects a date in a state dossier becomes part of the record. A retired teacher who shares a 1923 board minute moves the evidentiary floor by one entry. A state Department of Lands staff member who takes co-librarian responsibility for their state's page changes the standing of the collection, not just its contents. The Library does not have an audience and a staff. It has a constituency that is partly inside and partly outside the institutional wall, and the wall itself is permeable by design.
How the constituency gets built
Margaret Bird, who has spent four decades in school-trust administration, tells a story about Utah. When the state's school trust began publishing what each school received from its trust-lands distribution — naming the school, the principal, the amount, the year — the engaged constituency for the trust grew thirtyfold. The trust had not changed. The land had not changed. What changed was that people could see their own school named, their own principal named, the dollars that arrived because the trust existed. Recognition produced constituency. Constituency produced defense.
The Library is built on the same mechanism. Every finished document names its contributors. Every cited author appears in the document where they are cited. Every state correspondent and co-librarian is named on the state page they keep. Every submitter who supplies a primary source is named in the contributor record. The public stewardship ledger collects these names so a visitor can see who built what.
The reason is not flattery; it is institutional design. A library that names its people produces people who defend it. A library that does not produces people who pass through.
Editorial methodology and AI-assistance disclosure
The editorial team of record is Dave Sullivan and the OASTL litigation team, with substantive scholarly review by Margaret Bird on materials related to Schools of the Republic and the broader trust-lands record. The AI editorial collaborators are named: Claude (Anthropic), ChatGPT (OpenAI), Gemini (Google), and Grok (xAI). Each is used for drafting, cross-referencing, comparison across jurisdictions, and structural editing. None of them files a claim into the record without a human editor's verification against a primary source.
Materials authored primarily by an AI editorial pass carry an authorship line indicating so. Materials where the AI assistance was structural or referential do not. The distinction is recorded honestly; it is not used to launder AI-drafted material as human-written.
Citations are verified by a human editor against the cited source before publication. Corrections are dated; the Library does not silently overwrite its record of what it once said. The change log on each finished document records the evolution. The propagation log records the cross-document work.
The Library is in its first year of operation. The infrastructure described above is being built openly. Some pieces — the propagation log, the submission form, the validator program, the public "Building the Library" page — are at different stages of maturity. The "Building the Library" page tracks status weekly and is the place to check the current state of each piece.
Last updated 2026-05-24. The architecture posters are drawn from the OASTL knowledge architecture (April 2026), revised for the Library's purpose and audiences. The archived v1 of this page is preserved at /about/how-this-works/v1/.